Modern işletmelerin karşılaştığı en büyük zorluklardan biri, artan veri miktarları ve karmaşık hesaplama gereksinimlerini karşılayabilmektir. GPU (Graphics Processing Unit) server teknolojileri, bu zorluklara çözüm sunan en gelişmiş altyapı çözümlerinden biridir.
GTM Teknoloji GPU Sunucu Çözümleri ile Geleceği keşfedin..
Kurumsal HPC çözümleri, bilimsel hesaplama altyapıları ve yüksek performanslı GPU server sistemleri ile işletmenizi teknolojinin ön saflarına taşıyın.


İncele: Multi-GPU Scaling: Performansın Sınırlarını Aşmak ve Darboğazları Yönetmek
GPU Server Nedir? Yüksek Performanslı Hesaplama Geleceği
GPU Server Teknolojisinin Temelleri
GPU sunucuları, kuruluşları dönüştürerek yüksek performanslı bilgi işlem (HPC), yapay zeka (AI), makine öğrenimi (ML) ve derin öğrenmeyi mümkün kılar. Geleneksel CPU tabanlı sistemlerden farklı olarak, GPU’lar binlerce çekirdeği paralel olarak çalıştırabilir ve bu sayede karmaşık hesaplamaları çok daha hızlı gerçekleştirir.
🔧 Hizmetlerimiz
- GPU Server Tasarımı
- HPC Cluster Kurulumu
- AI Infrastructure Consulting
- Performance Optimization
- Hybrid Cloud Solutions
- Data Center Services
- 24/7 Monitoring & Support
Biyoinformatik ve Genomik
DNA dizileme, protein katlanma simülasyonları ve ilaç keşfi süreçlerinde GPU’lar, hesaplama süresini aylardan günlere indiriyor.
- Genom analizi: 1000x hızlanma
- Moleküler dinamik simülasyonları
- BLAST algoritmaları optimizasyonu
Mühendislik Simülasyonları
CFD (Computational Fluid Dynamics), FEA (Finite Element Analysis) ve yapısal analiz çalışmaları için optimize edilmiş çözümler.
- Aerodinamik simülasyonları
- Malzeme mühendisliği
- Deprem simülasyonları
Finansal Modelleme
Yapay zekâ sistemlerinden finans sektöründe de yararlanılıyor. Finansal piyasaların analizinde, yatırım stratejilerinin belirlenmesinde ve kredi risk değerlendirmelerinde yapay zekâ algoritmaları kullanılıyor.
- Monte Carlo simülasyonları
- Risk analizi modelleri
- Algoritmik ticaret
Büyük Dil Modelleri (LLM) ve Üretken Yapay Zeka
Milyarlarca parametreye sahip modellerin eğitimi ve çıkarım (inference) süreçlerinde; yüksek bant genişliği ve paralel işlem gücü sağlayan GPU kümeleri kritik rol oynar.
-
Model Eğitimi ve Fine-Tuning
-
RAG (Retrieval-Augmented Generation) Mimarileri
-
Doğal Dil İşleme (NLP) ve Kod Asistanları
GPU Server Teknolojisinin Temelleri: Hesaplamanın Yeni Çağı
GPU sunucuları, modern veri merkezlerinin kalbinde yer alarak kuruluşları dönüştürmekte; Yüksek Performanslı Bilgi İşlem (HPC), Üretken Yapay Zeka (GenAI), Makine Öğrenimi (ML) ve Derin Öğrenme süreçlerini mümkün kılmaktadır.
Geleneksel CPU tabanlı sistemler, sıralı işlem (serial processing) için optimize edilmiş az sayıda güçlü çekirdek kullanırken; GPU mimarisi, binlerce küçük ve verimli çekirdeğin paralel olarak çalıştığı devasa bir matris yapısına sahiptir. Bu yapı, karmaşık matematiksel yükleri ve veri setlerini, CPU’lara kıyasla yüzlerce kat daha hızlı işleyerek hesaplama süresini “aylardan saatlere” indirir.
Yeni Nesil Hesaplama Devleri: Mimariler ve Teknolojiler
Yapay zeka modellerinin parametre sayısı trilyonlara ulaştıkça, donanım dünyası da bu hıza ayak uydurmak için “Blackwell” ve “CDNA” gibi devrimsel mimarilere geçiş yapıyor. İşte sektörün oyun kurucuları:

NVIDIA Blackwell Mimarisi (B200 & B300 Serisi)
Yapay zekanın yeni çağı için tasarlanan Blackwell, sadece bir çip değil, tam bir platformdur.
-
NVIDIA B200: Önceki nesil Hopper mimarisine göre 30 kata kadar daha hızlı çıkarım (inference) performansı sunar. 208 milyar transistör içeren bu canavar, özellikle trilyon parametreli LLM (Büyük Dil Modelleri) eğitimi için optimize edilmiştir. Nvidia HGX tabanlı Supermicro ve Magnetar B200 sistemi, 8 adet her biri 180GB HBM3e belleğe sahip GPU’lar ile toplamda 1.4TB’lık devasa bir bellek havuzu sunar. Bu, trilyon parametreli modellerin (örneğin GPT-4 veya Llama 3 70B/400B) daha az sayıda sunucu ile “model parallel” olarak çalıştırılabilmesini sağlar.
-
NVIDIA B300: GB300 NVL72 gibi raf ölçeğindeki (rack-scale) süper bilgisayar tasarımlarının temel taşıdır. Bellek bant genişliği ve FP4 (Floating Point 4) hassasiyeti ile enerji verimliliğinde çığır açar. Nvidia HGX tabanlı Supermicro ve Magnetar B300 sistemi, 8 adet her biri 288GB HBM3e belleğe sahip GPU’lar ile toplamda 2.3TB’lık inanılmaz büyüklükte bir bellek havuzu sunar.
Bu kapasite, özellikle uzun bağlam pencereli (long context window) LLM uygulamaları (örneğin bir kitabın tamamını veya binlerce sayfalık hukuki dökümanı tek seferde işlemek) ve RAG (Retrieval-Augmented Generation) mimarileri için oyun değiştiricidir.

NVIDIA Hopper Mimarisi (H100 & H200)
Mevcut endüstri standardı olan Hopper, yapay zeka fabrikalarının ana motorudur.
-
1. NVIDIA DGX H200 (Bellek Canavarı)
-
8 adet NVIDIA H200 GPU içerir.
-
Sektördeki ilk HBM3e (High Bandwidth Memory 3e) kullanan GPU’dur.
-
141 GB GPU başına bellek ile toplamda 1.1 TB kapasiteye ulaşır.
-
4.8 TB/s bellek bant genişliği sunar (H100’e göre 1.4 kat daha hızlı).
-
Neden Önemli? Llama 70B gibi modelleri tek bir GPU üzerinde çalıştırma veya GPT-3 175B gibi modellerin çıkarım (inference) maliyetini yarıya indirme potansiyeli taşır. H100 sistemleriyle aynı anakart yapısını (baseboard) kullanır, yani fiziksel uyumluluğu tamdır.
2. NVIDIA DGX H100 (Endüstri Standardı)
-
8 adet NVIDIA H100 GPU içerir.
-
Standart olarak 80 GB HBM3 bellek ile gelir (İlk çıkan 94GB SXM versiyonları nadirdir, standart 80GB’dir).
-
Toplamda 640 GB bellek havuzu sunar.
-
3.35 TB/s bellek bant genişliğine sahiptir.
-
Neden Önemli? Halen dünyadaki çoğu AI eğitim kümesinin (cluster) bel kemiğidir. FP8 (Floating Point 8) hesaplamaları için optimize edilmiş Transformer Engine teknolojisini ilk getiren sistemdir.
-
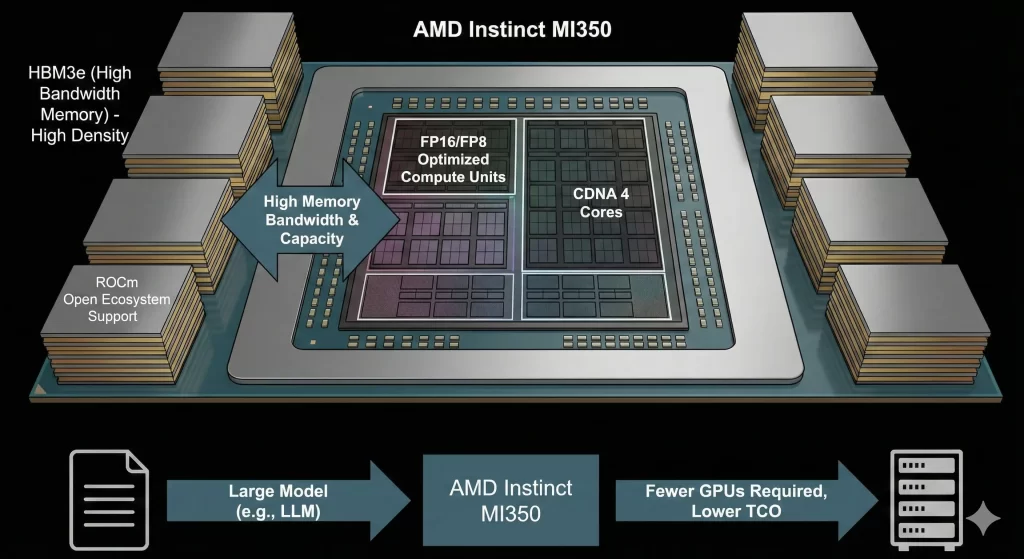
AMD Instinct™ MI350 ve CDNA Mimarisi
NVIDIA Blackwell serisi ile kafa kafaya rekabet etmek üzere tasarlanan MI350 ve MI355X (CDNA4), AMD’nin bugüne kadarki en büyük performans sıçramasıdır.
-
CDNA 4 Devrimi: Sadece yapay zeka çıkarımı (inference) için değil, eğitimi (training) için de optimize edilmiştir. Önceki nesil CDNA 3’e kıyasla işlem gücünde devasa bir artış sunar.
-
FP16 ve FP8 Hakimiyeti: Büyük Dil Modellerinin (LLM) ihtiyaç duyduğu düşük hassasiyetli hesaplamalarda (FP8), doğruluktan ödün vermeden maksimum verim sağlar.
-
Rakipsiz Bellek Kapasitesi: MI350 ve MI355x serisi, HBM3e bellek teknolojisi ile donatılmıştır. Bu sayede, trilyon parametreli modelleri belleğe sığdırmak için gereken GPU sayısını azaltır.
-
Örnek Senaryo: Rakip kartlarla 8 GPU gerektiren bir model, MI350’nin yüksek belleği sayesinde 4 GPU ile çalıştırılabilir. Bu, sunucu maliyetlerinde %50 tasarruf demektir.
-
AMD Instinct MI300X ve MI300A
AMD Instinct™: Yüksek Bellek Kapasitesi ve Açık Kaynak Gücü
Yapay zeka ve HPC dünyasında tek bir oyuncuya bağlı kalmak zorunda değilsiniz. AMD Instinct™ serisi, özellikle bellek yoğunluğu (memory density) ve bant genişliği konularında sunduğu devrimsel kapasitelerle, NVIDIA H100 ve B200 serilerinin en güçlü rakibi olarak sahneye çıkıyor.
AMD’nin stratejisi nettir: Daha fazla bellek, daha açık bir ekosistem ve işlemci başına daha yüksek verimlilik.
AMD Instinct MI300X (Saf GPU): Tek bir kartta tam 192 GB HBM3 bellek sunar. (NVIDIA H100’ün 80GB belleğinin 2.4 katıdır).
-
-
Avantajı: Llama 3 70B veya Falcon 180B gibi devasa modelleri tek bir kart üzerinde, hiçbir budama (quantization) yapmadan çalıştırabilirsiniz.
-
Bant Genişliği: 5.3 TB/s bellek bant genişliği ile veri darboğazlarını paramparça eder.
-
-
AMD Instinct MI300A (APU Teknolojisi): Dünyanın ilk veri merkezi APU’sudur. CPU ve GPU çekirdeklerini aynı silikon üzerinde birleştirir ve belleği ortak kullanır (Unified Memory). Özellikle HPC ve bilimsel simülasyonlar için veri kopyalama gecikmesini (latency) sıfıra indirir.
PCIe Tabanlı İnovasyon: Esneklik ve Gücün Mükemmel Dengesi
Her veri merkezi sıvı soğutmalı devasa SXM kabinlerine ihtiyaç duymaz. Kurumların çoğu; mevcut standart sunucu altyapılarına entegre edebilecekleri, hem yapay zeka çıkarımı (inference) hem de ağır grafik iş yüklerini (rendering, omniverse) aynı anda sırtlayabilecek çok yönlü (versatile) çözümler aramaktadır.
Her veri merkezi sıvı soğutmalı HGX sistemlerine veya özel raf tasarımlarına hazır değildir. NVIDIA NVL (NVLink) serisi, standart PCIe sunucu altyapısı içinde, özel süper bilgisayar performansı sunmak için tasarlanmıştır.
Bu kartlar, üzerlerinde bulunan özel NVLink Köprüleri (Bridges) sayesinde ikili veya 4’lü (Sadece H200 NVL) olarak çalışır ve PCIe veri yolunun darboğazına takılmadan birbirleriyle devasa hızlarda haberleşirler.
İşte NVIDIA’nın PCIe tabanlı yeni nesil şampiyonları:

NVIDIA H200 NVL : Standart Sunucularda Maksimum Ölçeklenebilirlik | 4x NVLink 564GB GPU Belleği
NVIDIA H200 NVL: Hız ve Belleğin Yeni Zirvesi
H100 NVL’nin başarısını, HBM3e bellek teknolojisi ile bir üst seviyeye taşır. Özellikle bellek darboğazı yaşayan üretken yapay zeka uygulamaları için oyun değiştiricidir.
-
HBM3e Farkı: H100 NVL’ye kıyasla 1.7 kata kadar daha fazla bellek kapasitesi ve 1.5 kata kadar daha fazla bellek bant genişliği sunar.
- MultiGPU NVLink Desteği: 2 veya 4 adet H200 NVL GPU birleştirilerek, 564GB GPU belleği oluşturulabilir.
-
Performans Sıçraması: Llama 3 70B gibi modellerde, H100 NVL’ye kıyasla 1.5x ile 1.7x arasında çıkarım (inference) performans artışı sağlar.
-
Enerji Verimliliği: Aynı güç tüketim aralığında (TDP) kalarak daha yüksek performans sunar, bu da mevcut enerji altyapısını değiştirmeden sunucu gücünü artırmak anlamına gelir.

NVIDIA H100 NVL: Standart Sunucularda Maksimum Ölçeklenebilirlik | 2x NVLink ile 188GB GPU Belleği
1. NVIDIA H100 NVL: Büyük Dil Modelleri İçin Tasarlandı
Standart H100 PCIe kartından (80GB) farklı olarak, NVL versiyonu daha yüksek bellek kapasitesi ve bant genişliği sunmak üzere özel olarak optimize edilmiştir.
-
MultiGPU Nvlink Mimarisi: İki adet PCIe kartın fiziksel bir köprü ile birleşmesiyle oluşur. Kart başına 94GB HBM3 bellek ile toplamda 188 GB sistem belleği sunar (Standart H100 PCIe’den daha fazladır). Bunun yanı sıra, İki GPU, PCIe Gen5 hızından 7 kat daha hızlı bir şekilde haberleşir. Bu, modelin iki karta bölünerek (Model Parallelism) çalıştığı senaryolarda hayati önem taşır.
-
Kullanım Senaryosu: GPT-3 175B gibi modellerin çıkarımı (inference) için idealdir. Hava soğutmalı (air-cooled) standart veri merkezi kabinlerine mükemmel uyum sağlar.

NVIDIA RTX 6000 Blackwell 96GB (Yeni Nesil İş İstasyonu ve AI Amiral Gemisi)
Profesyonel görselleştirme ve masaüstü yapay zeka geliştirmenin zirvesi. Ada Lovelace neslindeki 48GB sınırını aşarak, Blackwell mimarisiyle belleği 96GB seviyesine taşıması, onu sadece bir grafik kartı olmaktan çıkarıp “Kişisel Süper Bilgisayar” seviyesine yükseltiyor.
-
Kullanım Alanı: Büyük Ölçekli Dijital İkizler (Omniverse), 8K Video Düzenleme, LLM Fine-Tuning (Masaüstünde Llama-3 70B eğitimi).
-
Fark Yaratan Özellik: 96GB GDDR7 (veya yüksek yoğunluklu GDDR6) Bellek. Bu kapasite, daha önce sadece veri merkezi kartlarında (A100/H100) mümkündü. Artık mühendisler ve sanatçılar, buluta gitmeden devasa sahneleri ve modelleri yerel olarak işleyebilir.
-
NVIDIA RTX 5000 Blackwell 72GB
Fiyat/Performans dengesinde “Sweet Spot”. Önceki nesil RTX 5000 Ada’nın (32GB) üzerine devasa bir bellek koyarak, orta-üst segment sunucular ve iş istasyonları için ideal bir çözüm sunar.
NVIDIA L40S: Evrensel Veri Merkezi GPU'su (Ada Lovelace)
Bu kart, şu anda piyasanın “gizli kahramanıdır”. H100 bulmanın zor olduğu dönemlerde, özellikle Generative AI Inference (Üretken YZ Çıkarımı) için RTX 6000 Pro Blackwell’den sonra en güçlü alternatiftir.
-
Çok Yönlülük (Universal): H100 sadece hesaplama (compute) odaklıyken, L40S hem hesaplama hem de grafik (Ray Tracing) yeteneğine sahiptir.
-
AI Performansı: 48GB GDDR6 belleği ve güçlü Tensor çekirdekleri ile L40S, LLM çıkarımlarında (Inference) ve görsel üretim (Stable Diffusion, Midjourney benzeri) işlerinde inanılmaz bir performans sunar.
-
Avantajı: PCIe Gen4 arayüzü ile hemen hemen her sunucuya takılabilir. Ekstra özel soğutma veya güç altyapısı gerektirmez.

NVIDIA L4: Edge AI için Yüksek Verimlilik ve Video Uzmanı
Efsanevi NVIDIA T4’ün yerini alan, düşük profilli (low-profile) ve düşük güç tüketen (72W) bir mühendislik harikasıdır.
-
Video AI İşleme: L4, CPU’ya göre 120 kata kadar daha yüksek video performansı sunar. Akıllı şehir kameraları, video analitiği ve yayıncılık (transcoding) için rakipsizdir.
-
Enerji Verimliliği: Sunucu başına düşen işlem gücünü artırırken, enerji faturasını düşürür. Uç nokta (Edge) sunucuları için idealdir.
-
Tek Slot Yapısı: Yoğunluk (density) gerektiren sunucularda tek bir kasaya çok sayıda (örneğin 2U sunucuda 8-16 adet) sığdırılabilir.
GTM Teknoloji ile İşbirliği Yapmak
GTM Teknoloji olarak, neredeyse sınırsız yapılandırma olanaklarıyla, bir GPU sistemine yaptığınız yatırımın bugün ve ileride maksimum yatırım getirisi sağladığından emin olmak için kapsamlı danışmanlık hizmetleri sunuyoruz.
Analiz ve Planlama
İş yükü analizi, performans gereksinimleri değerlendirmesi. GTM Teknoloji, Nvidia NPN Elite Partner’dir.
Sistem Tasarımı
Özel GPU cluster mimarileri, ağ topolojisi optimizasyonu
Kurulum ve Konfigürasyon
Donanım kurulumu, yazılım optimizasyonu, benchmark testleri
Sürekli Destek
Proaktif izleme, performans optimizasyonu, sistem güncellemeleri