GPU ve TPU Mimarileri Savaşı: Esneklik mi, Saf Verimlilik mi?
Büyük Dil Modellerinin (LLM) yükselişi, yapay zeka donanımının da hızla gelişmesine neden oldu. Bu alanda Nvidia’nın GPU’ları ve Google’ın TPU’ları (Tensor İşleme Birimleri) olmak üzere iki ana mimari rekabet ediyor. Her ikisi de muazzam hesaplama gücü sunsa da, temelde farklı felsefelere dayanıyorlar. Bu blog yazısında, bu iki mimarinin çekirdek tasarımını, veri akışını ve büyük ölçekli küme topolojilerini karşılaştırarak, Google’ın neden "daha ucuz ve kısıtlayıcı" bir yolu seçtiğini inceleyeceğiz.
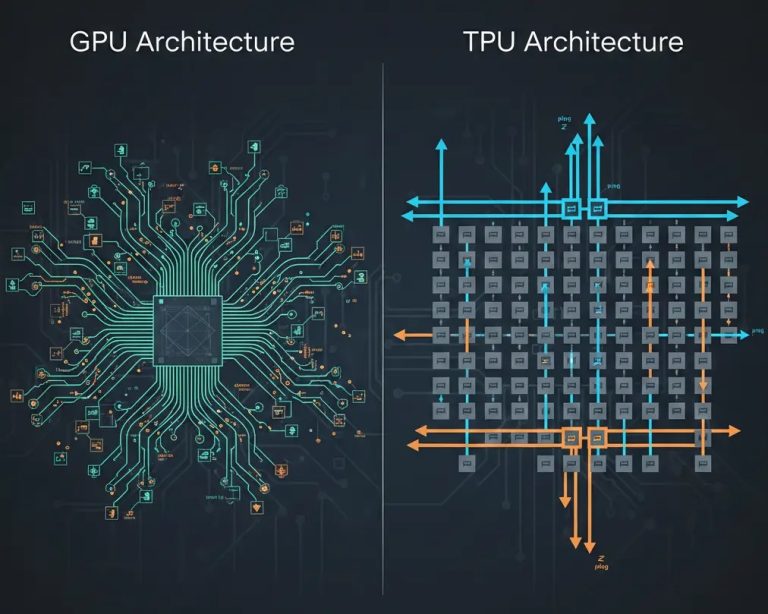
Hesaplama Çekirdeği: SIMT vs. Sistolik Dizi
Nvidia GPU: SIMT Mimarisi ve Esneklik
Nvidia GPU’lar, SIMT (Single-Instruction, Multiple-Threads / Tekil Talimat, Çoklu İplik) olarak bilinen bir yürütme modelini kullanır.
-
Çalışma Prensibi: Donanım, iş parçacıklarını 32’li gruplar halinde (“warp” denir) planlar ve yürütür. Bir warp içindeki tüm iş parçacıkları aynı anda aynı talimatı uygular.
-
Veri Akışı (Load-Store Modeli): Her iş parçacığı, ara sonuçları saklamak ve almak için kendi kayıt dosyalarından (register files) veya paylaşımlı bellek önbelleklerinden sürekli olarak veri çeker ve yazar. Bu sürekli okuma/yazma, gecikmeye neden olur.
-
Gecikmeyi Gizleme: Mimarinin temel gücü, bu gecikmeleri gizlemek için hızlı bağlam anahtarlaması (context-switching) yapabilmesidir. Veri bekleyen bir warp durduğunda, GPU hemen çalışmaya hazır başka bir warpa geçer.
-
Avantaj: Yüksek esneklik sağlar. Programcılar kodu tek bir iş parçacığı için yazabilir ve donanım bunu otomatik olarak binlerce iş parçacığına ölçekler. Düzensiz veri desenlerini ve hızlı değişen algoritmaları etkili bir şekilde yönetir. ****
Anahtar Not: Matrix çarpımı gibi özel işlemler (Tensor Çekirdekleri ile hızlandırılmış olsa bile) hala bu genel, iş parçacığı odaklı yürütme modeli içinde çalışır.
Google TPU: Sistolik Dizi ve Yoğun Aritmetik
Google TPU’ların kalbinde Sistolik Dizi (Systolic Array) adı verilen bir mimari bulunur. “Sistolik” terimi, kalbin kanı ritmik olarak pompalamasına benzer şekilde, verinin diziden ritmik akışını ifade eder.
-
Mimari: Birbirine bağlı işlem elemanlarından (çoğunlukla Matrix Çarpma Birimleri – MXU) oluşan büyük, iki boyutlu bir ızgaradır. TPU v6e’de (Trillium), iki adet 256×256 dizi bulunur.
-
Veri Akışı:
-
Ağırlıklar Durağan: Modelin ağırlıkları (weight) genellikle işlem elemanlarına önceden yüklenir ve sabit kalır.
-
Girdi Akışı: Giriş verileri (aktivasyonlar), ızgaraya bir yönden (örneğin soldan) akar.
-
Kısmi Toplam Akışı: Kısmi toplam sonuçları ise başka bir yönde (örneğin yukarıdan aşağıya) akar.
-
-
Doğrudan İletişim: Her saat döngüsünde, her bir işlem elemanı bir çarpma-toplama (multiply-and-accumulate) işlemi yapar ve sonucu belleğe yazmaya gerek kalmadan doğrudan yan komşusuna aktarır. ****
-
Avantaj: Aritmetik Yoğunluk (bellek erişimi başına yapılan hesaplama oranı) açısından rakipsizdir. Verinin sürekli olarak bellek/kayıt dosyası ile ALU arasında hareket etmesi çok enerji tüketicidir. Sistolik dizi, veriyi doğrudan ALU’lar arasında ileterek, her hesaplama başına düşen enerji maliyetini drastik olarak düşürür. Bu, özellikle yoğun matris çarpımı gerektiren modern LLM’ler için idealdir.
Küme Topolojisi: Fat-Tree vs. Torus
Mimari farkları, çipin ötesine, veri merkezi ağına kadar uzanır.
Nvidia Kümesi: Fat-Tree (Yaprak-Omurga) Topolojisi
Nvidia kümeleri, genişleme (scale-out) için genellikle Fat-Tree (Yaprak-Omurga) topolojisine güvenir.
-
Özellik: Küme içindeki her GPU, diğer her GPU’ya eşit uzaklıktadır (veya az sayıda tek atlamalı [single-hop] anahtar/switch üzerinden erişilebilir). Bu, tek tip gecikme ve yüksek bant genişliği sağlar.
-
Maliyet: Binlerce harici anahtar (switch) gerektirir. Bu esneklik, kümenin toplam gücünün ve sermaye maliyetinin %5-10’una mal olabilir.
-
Avantaj: Basit ve öngörülebilir ağ performansı.
Google TPU Pod’ları: Torus Topolojisi
Google ise TPU pod’ları için 2D veya 3D Torus topolojisini kullanır.
-
Özellik: Bu yaklaşım “glueless” (yapıştırıcısız) olup, ağ mantığı Inter-Chip Interconnect (ICI) portları aracılığıyla doğrudan çiplere entegre edilmiştir. TPU’lar yalnızca en yakın komşularına bağlanır. ****
-
Maliyet: Harici ağ anahtarlarına olan ihtiyacı ortadan kaldırarak maliyeti ve güç tüketimini önemli ölçüde azaltır.
-
Dezavantaj: Veri, kümenin bir köşesinden diğerine gönderilmek istendiğinde, birden fazla ara çip üzerinden çoklu atlama (multi-hop) yapmak zorundadır. Bu, komşu olmayan çip-çip iletişimi için gecikmeyi ve tıkanıklığı artırabilir. Yoğun matris çarpımı gibi düzenli iş yükleri için sorunsuzdur, ancak…
MoE Modelleri ve İletişim Darboğazı
Sistolik dizi ve Torus mimarisinin zarafeti, Mixture of Experts (MoE / Uzmanlar Karışımı) modelleriyle bir duvara çarpar.
-
MoE Sorunu: Yoğun modellerin aksine, MoE’de bir Yönlendirici (Router) katmanı, her bir token’ı farklı “Uzman” çiplere (genellikle komşu olmayan çipler) gönderir. Bu, aniden her TPU’nun diğer birçok TPU ile konuşması gerektiği anlamına gelen, “Hepsi-Hepsine” (All-to-All) bir trafik düzeni oluşturur.
-
Torus’ta Tıkanıklık: 3D Torus’ta bu “Hepsi-Hepsine” trafiği, verinin onlarca ara çip üzerinden atlamasını gerektirir. Bu ara çipler, kendi hesaplama yeteneklerini durdurarak sadece trafik yönlendirmekle meşgul olur ve gecikme (latency) artar, eğitim verimliliğini düşürür.
Google’ın Çözümü: Bükülmüş Torus (Twisted Torus) ve OCS
Google, Torus’un maliyet avantajlarından vazgeçmeden bu tıkanıklığı çözmek için yazılım ve donanım optimizasyonlarını birleştirdi:
-
Twisted Torus: TPU v4 ile başlayarak, Optik Devre Anahtarları (OCS) sistemi tanıtıldı. OCS, geleneksel paket anahtarlarının aksine, fiziksel olarak ışık demetlerini yansıtarak küme bağlantı yollarını modelin gerektirdiği veri akışına göre yeniden kablolayabilir.
-
Etki: Bu sayede ağ, sadece en yakın komşulara değil, uzaktaki komşulara da bağlanacak şekilde “bükülür”. Bu, ağ çapını (iki çip arasındaki ortalama atlama sayısı) önemli ölçüde azaltır. Bir TPU v4 makalesi, bükülmüş bir Torus’un, düzenli bir Torus’a göre “Hepsi-Hepsine” aktarım hızını 1.31x ila 1.63x oranında iyileştirdiğini rapor etmiştir. ****
Sonuç: TCO ve Felsefi Fark
Google neden bu kadar karmaşık bir yolda (Sistolik Dizi + Çok Atlama Torus) ısrar ediyor? Cevap, Toplam Sahip Olma Maliyetinde (TCO) yatıyor:
-
TPU: Basit, ucuz, düşük güçlü Toroidal ağ mimarisi ile süper verimli, ancak yazılımsal olarak karmaşık Sistolik Dizi mimarisini birleştirir.
-
Nvidia: Maksimum esneklik için, karmaşık SIMT mimarisi ile pahalı, yüksek güçlü, tek atlamalı Fat-Tree ağını birleştirir.
Google’ın stratejisi şudur: Sistolik dizi ile daha az enerji/para ile daha fazla hesaplama elde et, ve Torus ile pahalı ağ anahtarlarını ortadan kaldırarak maliyeti düşür. Ortaya çıkan karmaşıklık, XLA gibi gelişmiş derleyiciler ve yazılım optimizasyonları ile yönetilir.
Bu, Google’ın esneklik yerine verimlilik için büyük bir risk aldığı anlamına geliyor. Nvidia’nın gücü geliştirici ekosisteminde (CUDA) ve esneklikteyken, Google’ın gücü ölçek ve maliyet verimliliğinde yatmaktadır.
TPU’ların Apple ve Anthropic gibi büyük oyuncular tarafından benimsenmesi, bu mimarinin bir geleceği olduğunu gösteriyor. Ancak, Google’ın kendi içindeki avantajının (donanım ve derleyiciyi tasarlayan aynı şirket olması) ne kadarının saf mimari üstünlük olduğu, bağımsız karşılaştırmalı testler olmadan tam olarak anlaşılamamıştır.
Kaynak: Sharada Yeluri – Astera Labs
Sizin İş Yükünüz için Hangisini Seçmeli?
Kendi yapay zeka modelinizi eğitirken TPU’ların saf verimliliğinden mi, yoksa GPU’ların geniş ekosisteminden mi faydalanmalısınız? İş yükünüz için en uygun mimariyi belirlemek üzere bizimle iletişime geçin ve uzman tavsiyelerimizden yararlanın.
Hemen İletişime GeçinHemen İletişime Geçin