Multi-GPU Scaling: Performansın Sınırlarını Aşmak ve Darboğazları Yönetmek
Yapay zeka modellerinin parametre sayıları milyarlardan trilyonlara çıkıyor. Tek bir GPU—ne kadar güçlü olursa olsun—artık yeterli değil. İşte bu noktada Multi-GPU Scaling (Çoklu GPU Ölçekleme) devreye giriyor. Ancak, sunucuya sadece daha fazla kart takmak performansı doğrusal olarak artırmaz.
Bu yazıda, Multi-GPU ölçeklemenin mantığını anlayacağız. Karşılaşılan darboğazları (bottlenecks) ve maksimum verim (throughput) için uygulamanız gereken stratejileri inceliyoruz.
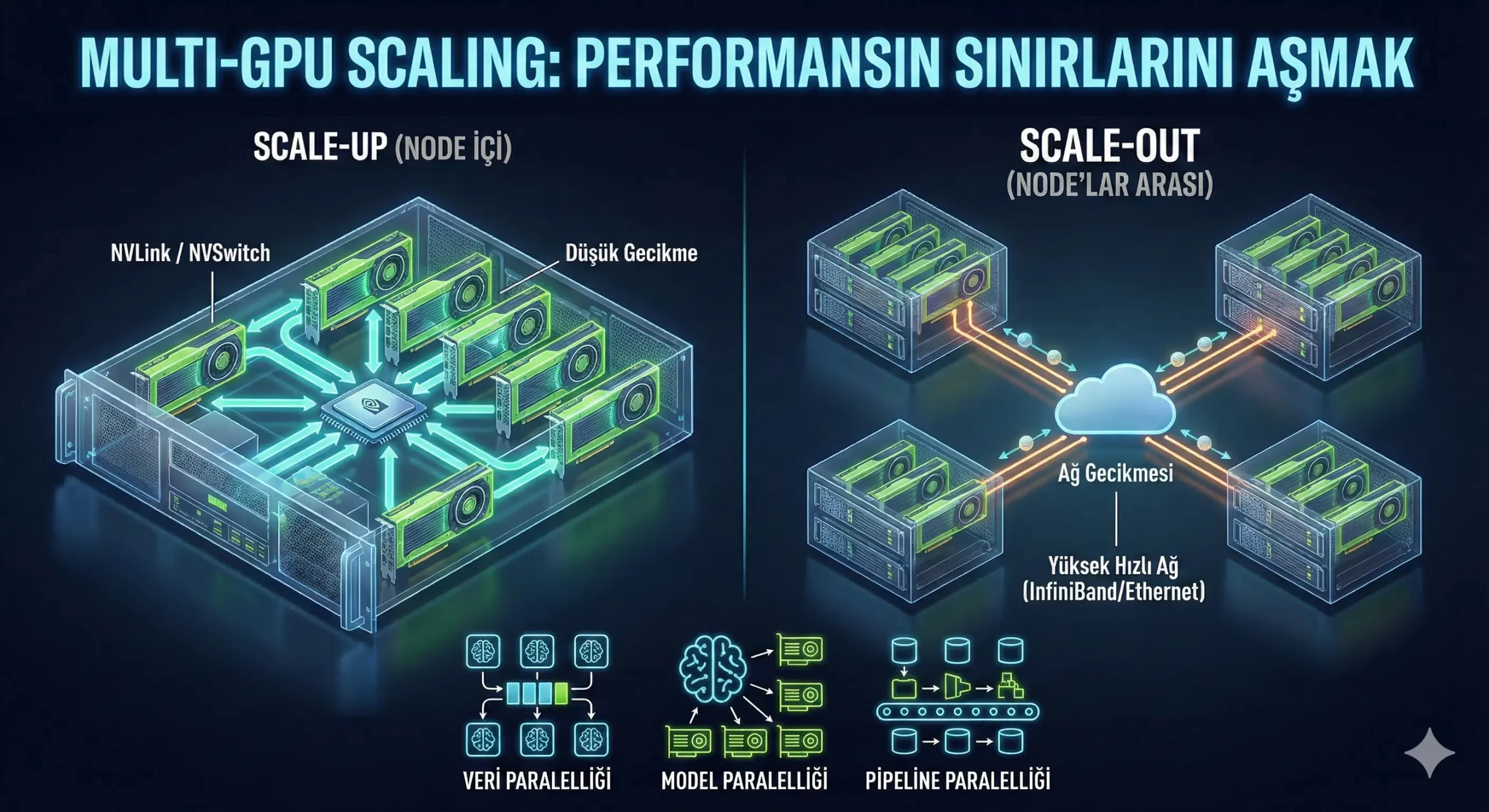
Ölçekleme Türleri: Scale-Up vs. Scale-Out
Multi-GPU mimarisini anlamak için önce iki temel yaklaşımı birbirinden ayırmalıyız:
Scale-Up (Dikey Ölçekleme - Node İçi)
Tek bir sunucu (node) içerisindeki GPU sayısını artırmaktır.
-
Örnek: Bir kasada 4 veya 8 adet H100 veya A100 GPU bulunması.
-
Avantajı: GPU’lar arası iletişim çok hızlıdır. (NVLink/NVSwitch sayesinde). Gecikme (latency) düşüktür.
-
Sınırı: Fiziksel alan, güç tüketimi ve PCIe hattı sınırları. (genellikle node başına 8-16 GPU).
Scale-Out (Yatay Ölçekleme - Node'lar Arası)
Birden fazla sunucunun birbiriyle bağlanarak devasa bir süper bilgisayar gibi çalışmasıdır.
-
Örnek: GPU Cluster yapıları, SuperPOD mimarileri.
-
Kritik Bileşen: Burada devreye yüksek hızlı ağlar girer. (InfiniBand NDR, 400G/800G Ethernet).
-
Zorluğu: Ağ gecikmesi (Network Latency) performansın en büyük düşmanıdır.
İletişim Darboğazı: "Compute" vs. "Communication"
Multi-GPU sistemlerdeki en büyük yanılgı şudur: “2 GPU, 1 GPU’dan 2 kat hızlıdır.” Gerçekte ise Amdahl Yasası ve iletişim maliyetleri (overhead) devreye girer.
GPU’lar işlem yaparken (Compute) inanılmaz hızlıdır. Ancak birbirleriyle veri paylaşırken (Communication) beklemek zorunda kalırlarsa sistem yavaşlar.
Bunu Aşmanın Yolu: Interconnect Teknolojileri
Standart PCIe darboğazını aşmak için özel ara bağlantılar kullanılır:
-
NVLink & NVSwitch: GPU’ların belleği (VRAM) birbirine doğrudan bağlamasını sağlar. Sanki tek ve devasa bir GPU varmış gibi çalışır. PCIe Gen5’ten 7-10 kat daha fazla bant genişliği sunar.
-
GPUDirect RDMA: Verinin CPU’ya uğramadan, doğrudan bir GPU’nun belleğinden diğer node’daki GPU’nun belleğine (InfiniBand/RoCE üzerinden) aktarılmasıdır.
Paralelleştirme Stratejileri
Modeliniz tek bir GPU’nun belleğine sığmayabilir. Veya eğitim süresi çok uzun sürebilir. İşte tamda bu durumda, iş yükünü nasıl böleceğiniz performansı belirleyen yegane unsurdur.
Multi-GPU Scaling'de Başarı İçin 5 Altın Kural
Bir sistem mimarı veya yapay zeka mühendisi olarak dikkat etmeniz gerekenler:
-
Topology Awareness (Topoloji Farkındalığı): GPU’larınızın anakart üzerinde nasıl bağlı olduğunu bilin. NVLink ile bağlı GPU çiftleri arasındaki iletişim, PCIe üzerinden bağlı olanlardan çok daha hızlıdır. İş yükünüzü buna göre atayın (NUMA affinity).
-
Batch Size Optimizasyonu: Çok küçük batch size, GPU’nun tam kapasite çalışmasını engeller (Underutilization). Çok büyük batch size ise “Out of Memory” hatası verir. Sweet spot’u bulun.
-
Hızlı Depolama (Storage): GPU’lar veriyi işlerken hıza ihtiyaç duyar. Depolama biriminin (NVMe SSD) veriyi GPU’ya yeterince hızlı besleyebilmesi gerekir. Aksi takdirde GPU’lar boşta bekler (GPU Starvation).
-
Termal Yönetim: 8 adet 700W’lık GPU aynı anda çalıştığında oluşan ısı, saat hızlarının düşmesine (Throttling) neden olabilir. Soğutma, performansın gizli kahramanıdır.
-
Doğru Kütüphaneler: NCCL (NVIDIA Collective Communications Library) gibi kütüphanelerin güncel ve optimize olduğundan emin olun. Yazılım katmanı, donanım gücünü orkestre eden şeftir.
Sonuç: Yatırımın Karşılığını Almak
Multi-GPU sistemler pahalı yatırımlardır. Bu sistemlerden %90+ verimlilik almak (Scaling Efficiency) ile %50 verimlilikle çalıştırmak arasındaki fark, doğru mimari kurgu ve yazılım optimizasyonudur.
Gelecek, sadece daha güçlü GPU’larda değildir. Bu GPU’ların birbiriyle ne kadar uyumlu çalışabildiği (Interconnectivity) üzerinde şekillenecektir.