

GB200 NVL72 raf ölçekli sistem, dokuz NVLink anahtar tepsisine ve GPU’ları ve anahtarları birbirine bağlayan kablo kartuşlarına sahip NVIDIA NVLink Anahtar Sistemini kullanarak 18 hesaplama düğümü için paralel model verimliliğini kolaylaştırır.
NVIDIA GB200 NVL36 ve NVL72
GB200, NVLink etki alanlarında 36 ve 72 GPU’yu destekler. Her raf, MGX referans tasarımına ve NVLink Anahtar Sistemine dayalı 18 hesaplama düğümünü barındırır. Tek rafta 36 GPU ve 18 tek GB200 bilgi işlem düğümüyle GB200 NVL36 yapılandırmasında gelir. GB200 NVL72, bir rafta 72 GPU ve 18 çift GB200 hesaplama düğümüyle veya 18 tek GB200 hesaplama düğümüne sahip iki rafta 72 GPU ile yapılandırılmıştır.
GB200 NVL72, işletim kolaylığı için bakır kablo kartuşu kullanarak GPU’ları yoğun bir şekilde paketler ve birbirine bağlar. Aynı zamanda 25 kat daha düşük maliyet ve enerji tüketimi sağlayan bir sıvı soğutma sistemi tasarımı kullanıyor.

Beşinci Nesil NVLink ve NVLink Anahtar Sistemi
NVIDIA GB200 NVL72, 1 PB/s’nin üzerinde toplam bant genişliği ve 240 TB hızlı bellekle tek bir NVLink etki alanında 576’ya kadar GPU’yu bağlayan beşinci nesil NVLink’i sunar. Her NVLink anahtar tepsisi 100 GB’ta 144 NVLink bağlantı noktası sunar; böylece dokuz anahtar, 72 Blackwell GPU’nun her birindeki 18 NVLink bağlantı noktasının her birine tam olarak bağlanır.
GPU başına devrim niteliğindeki 1,8 TB/s çift yönlü çıkış, PCIe Gen5’in bant genişliğinin 14 katından fazladır ve günümüzün en karmaşık büyük modelleri için kesintisiz yüksek hızlı iletişim sağlar.

Nesiller boyunca NVLink
Yüksek hızlı, düşük güçlü SerDe’lere yönelik NVIDIA’nın sektör lideri yeniliği, çoklu GPU iletişimlerini yüksek hızda hızlandırmak için NVLink’in tanıtılmasıyla başlayarak GPU’dan GPU’ya iletişimin ilerlemesini sağlıyor. NVLink GPU’dan GPU’ya bant genişliği 1,8 TB/s’dir; bu, PCIe bant genişliğinin 14 katıdır. Beşinci nesil NVLink, 2014’te tanıtılan 160 GB/sn hızıyla ilk nesilden 12 kat daha hızlıdır. NVLink GPU’dan GPU’ya iletişim, yapay zeka ve HPC’de çoklu GPU performansının ölçeklendirilmesinde etkili olmuştur.
GPU bant genişliğindeki ilerlemeler, NVLink alan boyutunun katlanarak genişlemesiyle birleştiğinde, bir NVLink alanının toplam bant genişliğini 2014’ten bu yana 900 kat artırarak 576 Blackwell GPU NVLink alanı için 1 PB/s’ye çıkardı.
Kullanım örnekleri ve performans sonuçları
GB200 NVL72’nin bilgi işlem ve iletişim yetenekleri benzersiz olup, yapay zeka ve HPC’deki büyük zorlukları pratik erişime taşıyor.
Yapay zeka eğitimi
GB200, FP8 hassasiyetine sahip daha hızlı bir ikinci nesil transformatör motoru içerir. Aynı sayıdaki NVIDIA H100 GPU’lara kıyasla GPT-MoE-1.8T gibi büyük dil modelleri için 32k GB200 NVL72 ile 4 kat daha hızlı eğitim performansı sunar.
Yapay zeka çıkarımı
GB200, LLM çıkarım iş yüklerini hızlandıran son teknoloji yetenekleri ve ikinci nesil bir transformatör motorunu sunar. Önceki H100 nesline kıyasla 1,8T parametresi GPT-MoE gibi yoğun kaynak kullanan uygulamalar için 30 kat hızlanma sağlar. Bu ilerleme, FP4 hassasiyetini ve beşinci nesil NVLink’in getirdiği pek çok avantajı sunan yeni nesil Tensör Çekirdekleri ile mümkün olmaktadır.
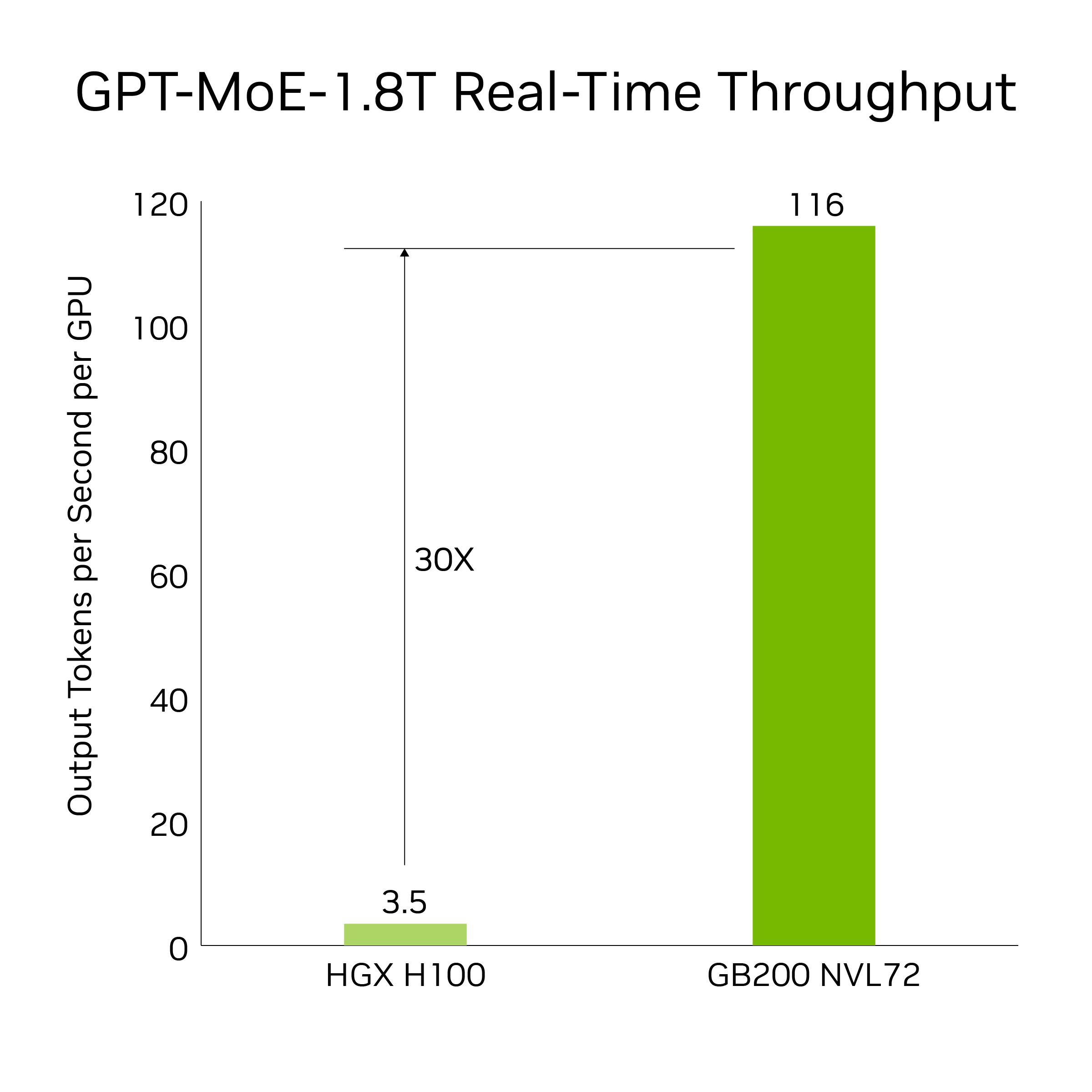
Belirteçler arası gecikmeye dayalı sonuçlar = 50 ms; gerçek zamanlı, ilk jeton gecikmesi = 5.000 ms; giriş dizisi uzunluğu = 32.768; çıkış sırası uzunluğu = 1.024 çıkış, 8x sekiz yollu HGX H100 hava soğutmalı: 400 GB IB Ağ vs 18 GB200 Superchip sıvı soğutmalı: NVL36, GPU performans karşılaştırmasına göre. Tahmini performans değişebilir.
30 kat hız artışı, 8 yönlü NVLink ve InfiniBand üzerinden ölçeklendirilmiş 64 NVIDIA Hopper GPU’yu, GPT-MoE-1.8T kullanan GB200 NVL72’deki 32 Blackwell GPU ile karşılaştırıyor.
Veri işleme
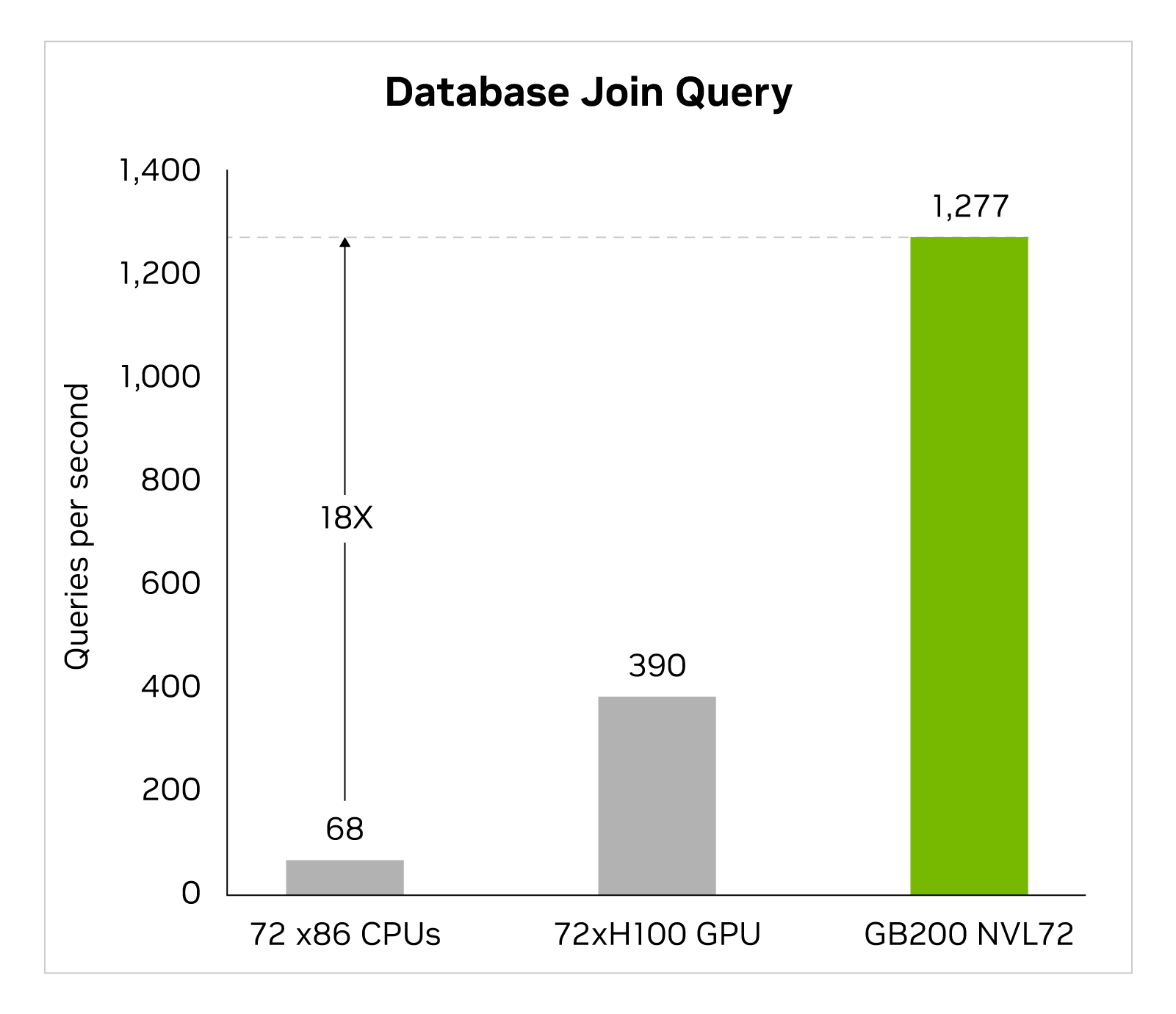
Büyük veri analitiği, kuruluşların içgörüleri açığa çıkarmasına ve daha bilinçli kararlar almasına yardımcı olur. Kuruluşlar sürekli olarak uygun ölçekte veri üretir ve darboğazları hafifletmek ve depolama maliyetlerinden tasarruf etmek için çeşitli sıkıştırma tekniklerinden yararlanır. Bu veri kümelerini GPU’larda verimli bir şekilde işlemek için Blackwell mimarisi, sıkıştırılmış verilerin sıkıştırmasını yerel olarak geniş ölçekte açabilen ve analiz hatlarını uçtan uca hızlandırabilen bir donanım açma motoru sunar. Sıkıştırılmış açma motoru, LZ4, Deflate ve Snappy sıkıştırma formatları kullanılarak sıkıştırılmış verilerin sıkıştırılmasını açmayı doğal olarak destekler.
Sıkıştırmayı açma motoru belleğe bağlı çekirdek işlemlerini hızlandırır. 800 GB/s’ye kadar performans sağlar ve Grace Blackwell’in sorgu kıyaslamaları için CPU’lardan (Sapphire Rapids) 18 kat, NVIDIA H100 Tensor Core GPU’lardan 6 kat daha hızlı performans göstermesini sağlar.
Çarpıcı 8 TB/sn’lik yüksek bellek bant genişliği ve Grace CPU’nun yüksek hızlı NVlink-Chip-to-Chip (C2C) özelliği ile motor, veritabanı sorgularının tüm sürecini hızlandırır. Bu, veri analitiği ve veri bilimi kullanım senaryolarında birinci sınıf performansla sonuçlanır. Bu, kuruluşların maliyetlerini azaltırken hızlı bir şekilde içgörü elde etmelerini sağlar.
Fizik tabanlı simülasyonlar
Fizik tabanlı simülasyonlar hâlâ ürün tasarımı ve geliştirmenin temel dayanağıdır. Uçaklardan trenlere, köprülerden silikon çiplere ve hatta ilaçlara kadar ürünlerin simülasyon yoluyla test edilmesi ve iyileştirilmesi milyarlarca dolar tasarruf sağlıyor.
Uygulamaya özel entegre devreler, voltajları ve akımları tanımlamak için analog analiz de dahil olmak üzere, uzun ve karmaşık bir iş akışında neredeyse yalnızca CPU’lar üzerinde tasarlanmıştır. Cadence SpectreX simülatörü bir çözücü örneğidir. Aşağıdaki şekil SpectreX’in GB200’de x86 CPU’ya göre 13 kat daha hızlı çalıştığını göstermektedir.
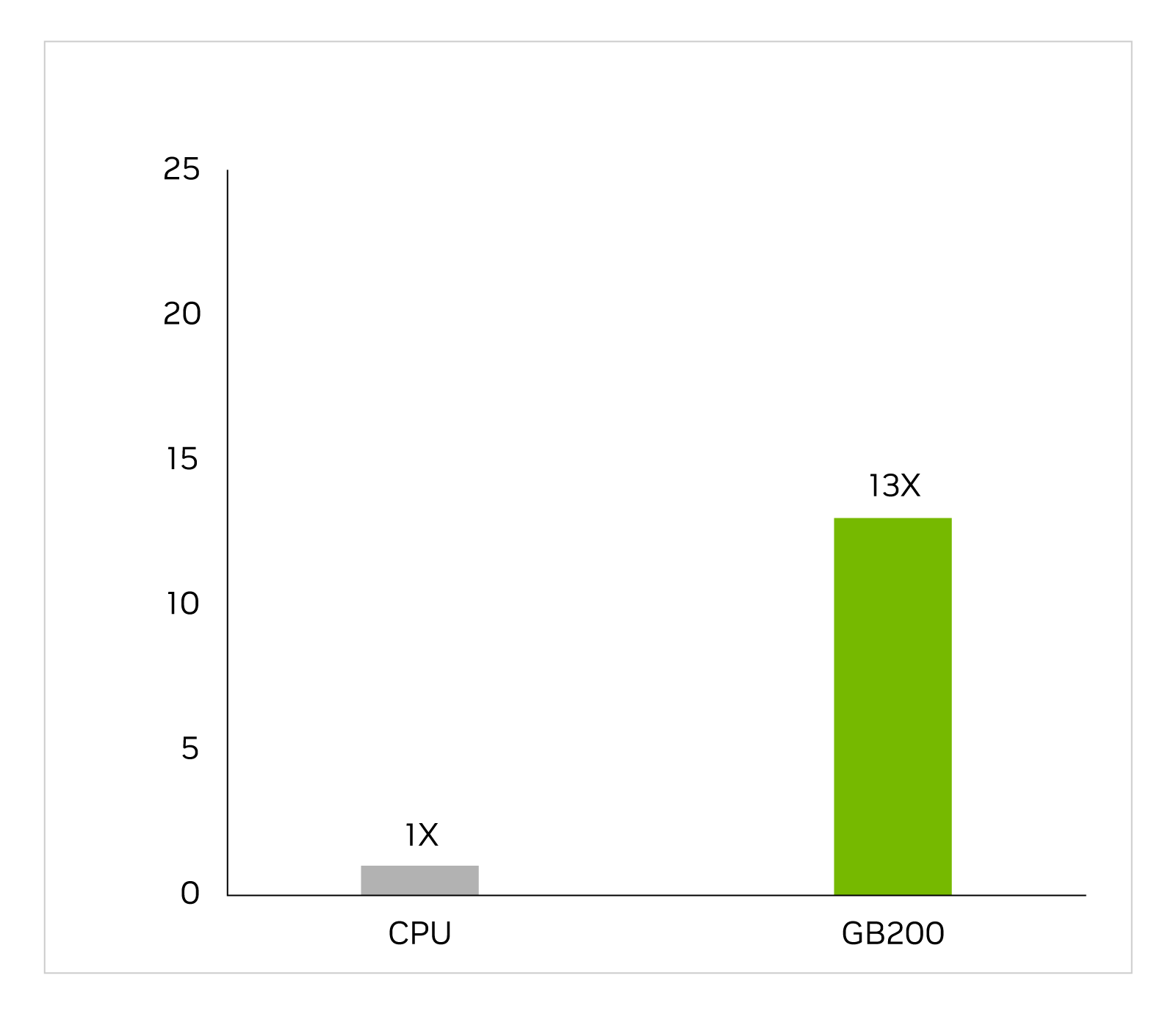
Cadence SpectreX (Baharat simülatörü) | CPU: 16 çekirdek AMD Milan 75F3 veri kümesi: KeithC Design TSMC N5 | GB200 için performans projeksiyonları değişebilir
Son iki yılda sektör, temel bir araç olarak GPU ile hızlandırılmış hesaplamalı akışkanlar dinamiğine (CFD) giderek daha fazla yöneldi. Mühendisler ve ekipman tasarımcıları bunu tasarımlarının davranışını incelemek ve tahmin etmek için kullanır. Büyük bir girdap simülatörü (LES) olan Cadence Fidelity, simülasyonları GB200’de x86 CPU’ya göre 22 kata kadar daha hızlı çalıştırır.
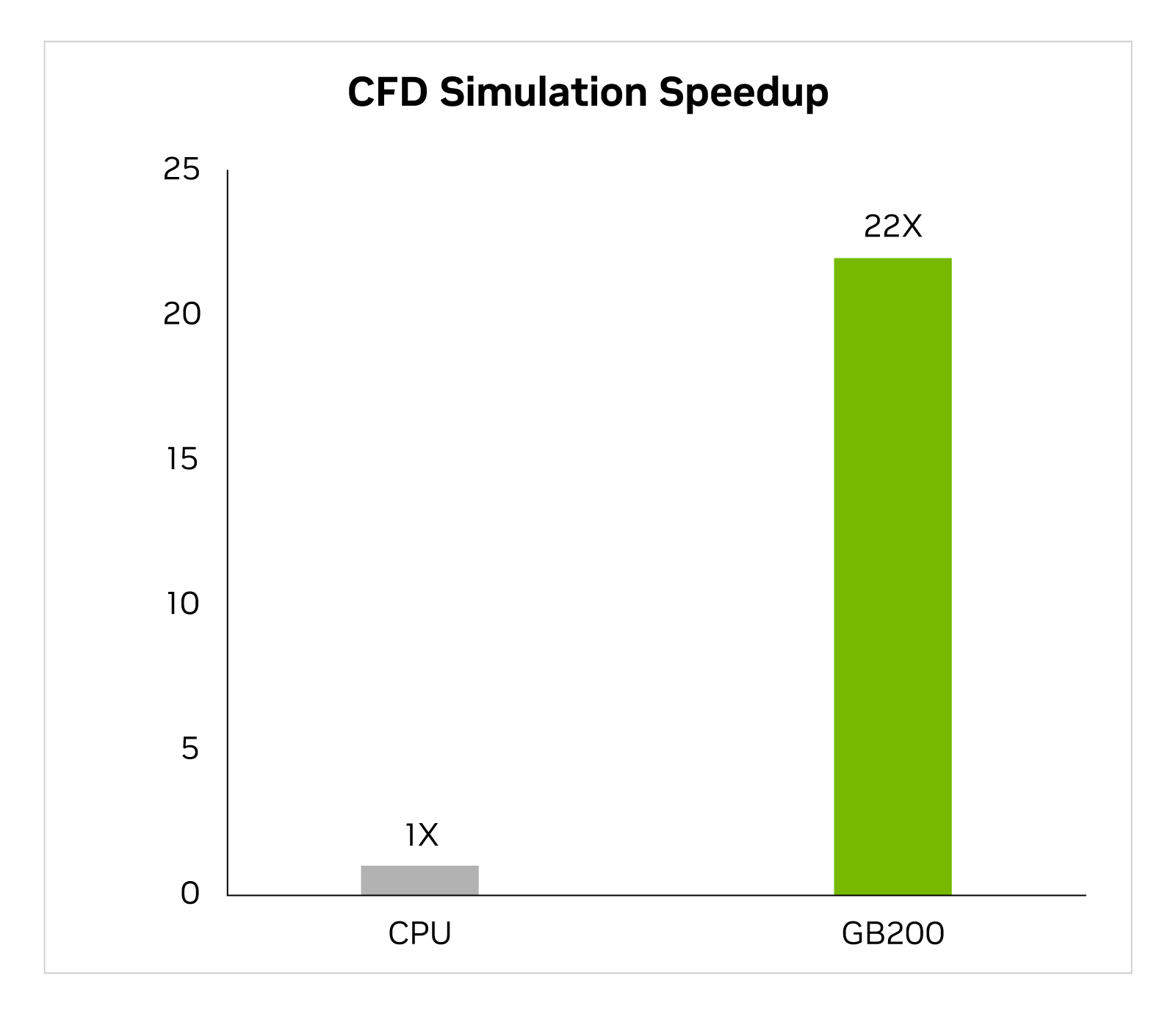
Cadence Fidelity (LES CFD Çözücü)| CPU: 16 çekirdek AMD Milan 75F3 Veri kümesi: GearPump 2M hücre | GB200 için performans projeksiyonları değişebilir
GB200 NVL72’de Cadence Fidelity’nin olanaklarını keşfetmeyi sabırsızlıkla bekliyoruz. Paralel ölçeklenebilirlik ve raf başına 30 TB bellek ile daha önce hiç yakalanmamış akış ayrıntılarını yakalamayı hedefliyoruz.
Özet
Özetlemek gerekirse, GB200 NVL72 raf ölçekli tasarımını inceledik ve özellikle tek bir NVIDIA NVLink alanı üzerinden 72 Blackwell GPU’yu bağlama konusundaki benzersiz yeteneğini öğrendik. Bu, geleneksel ağlar üzerinden ölçeklendirme yapılırken karşılaşılan iletişim yükünü azaltır. Sonuç olarak, 1.8T parametreli bir MoE LLM için gerçek zamanlı çıkarım mümkün oluyor ve bu modelin eğitimi 4 kat daha hızlı oluyor.
72 adet NVLink bağlantılı Blackwell GPU’nun 30 TB birleşik belleğe sahip 130 TB/s işlem yapısı üzerinden çalıştırılması, tek bir rafta exaFLOP AI süper bilgisayarı oluşturur. Bu NVIDIA GB200 NVL72’dir.